Mar 27, 2026
AI Development Playbook
From initial steps to production-grade delivery, this is a practical guide for teams building with AI.
For CTOs
Founders
Engineering Leaders

May 25, 2026

Development
Where Are You Starting From?
AI-assisted development involves two distinct journeys. This playbook addresses both.
Just Getting Started?
You haven't committed to AI-assisted development yet, but you're watching competitors move faster and wondering if the risk is worth it.
Good news: starting right is far easier than fixing a broken rollout. This playbook gives you the structure to begin safely, incrementally, and with full team confidence.
- No need to overhaul your stack overnight
- No need to hire new people before you start
- Start in one phase, expand when it's working
Already Hit the Wall?
PR volume went up. So did review anxiety, rework, and production incidents. Pilots looked great. Production was noisy.
You're not alone, and the problem is almost never the model. It's the missing operating layer around it.
This playbook shows you exactly what that layer looks like.
- Identify the specific gap that caused your wall
- Install governance without slowing the team
- Rebuild production trust in 3 weeks
Why AI-First Struggles in Production
Whether you're starting out or course-correcting, knowing the failure modes in advance is the highest-ROI move you can make. The problem is almost never model quality. It's the operating discipline around it.
| Root Cause | What It Produces | How to Avoid It |
|---|---|---|
| Weak discovery | Vague requirements → wrong code generated at scale | Define testable acceptance criteria before any AI writes a line |
| No control layer | Anything gets generated — no architecture guardrails | Establish assertive rules: "never do X" beats "prefer Y" |
| Optional verification | Quality debt compounds under time pressure | Automate your gate: Lint → Type-check → Tests → Build → Integration |
| No operational closure | Changes ship without monitoring or human ownership | Every merged change ships with logs, metrics, and a named owner |
| Integration blind spots | External services treated as connectors, not orchestration points | Map dependencies and failure modes before build begins |
"Pilots look good. Production becomes expensive. The gap between the two is always process, not talent."
The End-to-End AI Delivery Pipeline
AI only becomes reliable when it runs through the full delivery lifecycle, not just the code-generation AI becomes reliable only when it is integrated throughout the entire delivery lifecycle, not just during code generation. Most teams move directly to the build phase, while successful teams follow every step.
Below is our vision of AI across the delivery pipeline.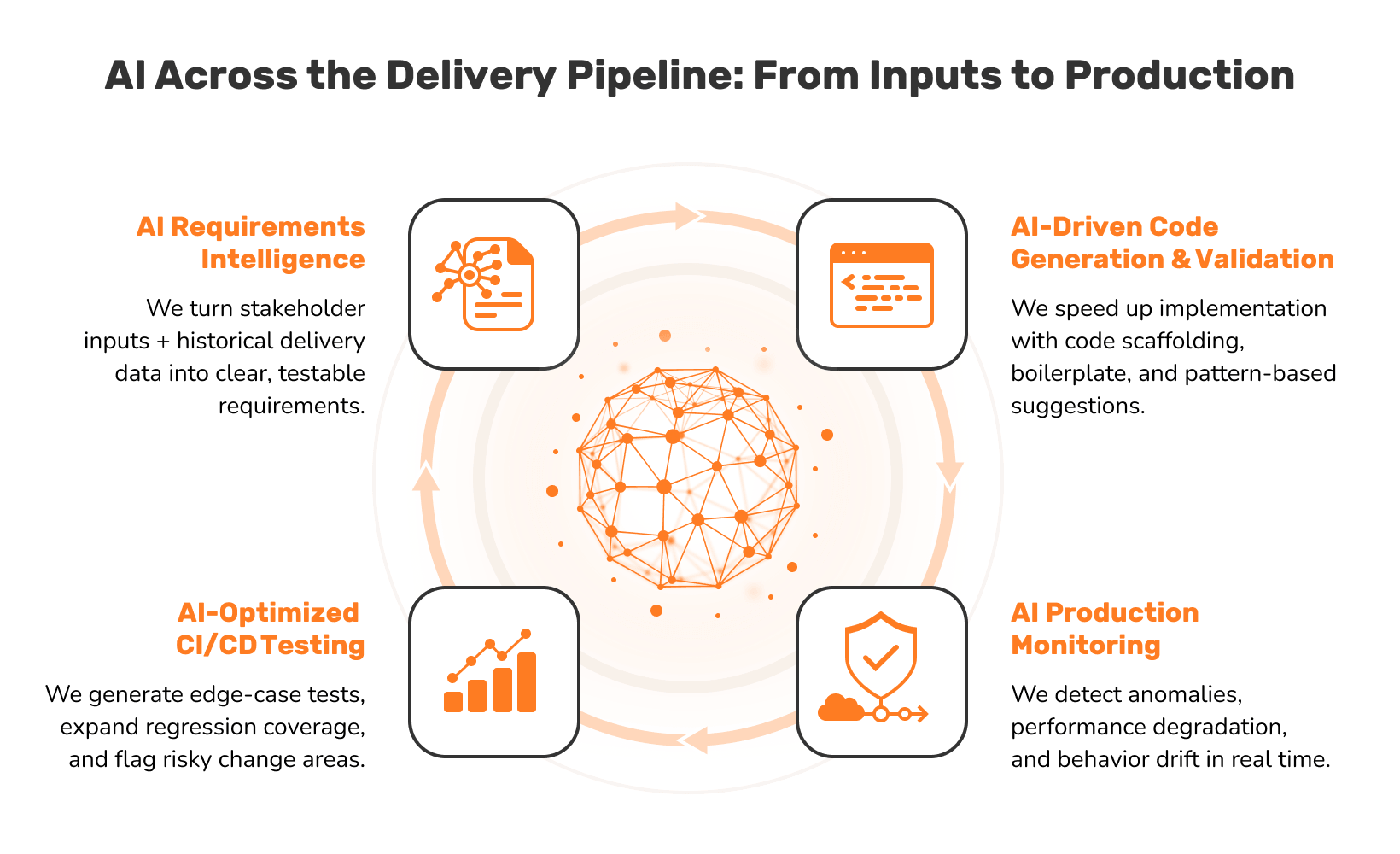
| Phase | Capability | What It Delivers |
|---|---|---|
| DISCOVER | Requirements Intelligence | Turn stakeholder inputs into testable requirements and clear acceptance criteria before any code is written |
| BUILD | AI Codegen with Governance | Generate implementation inside explicit constraints: architecture boundaries, security rules, codebase patterns |
| VERIFY | AI-Optimised CI/CD | Expand edge-case coverage, prevent regressions, enforced by automated pipeline gates |
| OPERATE | Production Monitoring | Detect anomalies and drift early. Keep human ownership intact for fast, AI-thread-free incident response |
If you're just starting:
This is your highest-leverage first step. Define what to build clearly, and AI will accelerate you from day one.
If you've hit the wall:
Vague requirements are the #1 root cause of AI-first failures. Fix this first.
AI amplifies direction. If intent is unclear before code generation, mistakes multiply rapidly. A clear discovery phase is essential for AI teams to avoid costly rework.
Non-Negotiables Before You Build
| Element | What It Means |
|---|---|
| Acceptance criteria | Written and testable — not vague or implied. If you can't test it, it's not a requirement. |
| Edge cases | Named upfront: failure modes, data issues, integration limits. AI generates for the happy path unless you define the exceptions. |
| Scope boundaries | Explicit — what's out is as important as what's in. AI fills ambiguity with assumptions. |
| Definition of Done | Includes observability + rollback plan. If it ships, it must be diagnosable and reversible. |
Output Standard — What "Ready to Build" Looks Like

Principle 1
Human Ownership Is Non-Negotiable
Every merged line must have a human owner who understands its function, can debug it under pressure, and is accountable for its production impact and ongoing support.
"Policy: AI can assist. Humans merge. If it ships, someone can support it — without the AI thread."
Principle 2
Systematise AI Usage (Rules > Prompting)
High-performing teams do not rely solely on prompting. They establish a repeatable operating model that remains effective regardless of who writes the code.
| Layer | What It Is | How It Works |
|---|---|---|
| Rules | Persistent guardrails | Architecture boundaries · code style · security constraints · anti-patterns. Make them assertive: "never do X" beats "prefer Y." |
| Skills | Repeatable procedures | Create PR with changelog · generate scaffolding · run review checklist · refactor in module boundaries. Must run without mid-execution clarification. In practice: the team has moved to Claude Code as the primary coding interface. Skills are evolving rapidly ? hundreds exist, and the relevant set changes weekly as better options emerge. A recommended starting point: github.com/obra/superpowers. Treat skill selection as a living decision, not a one-time setup. |
| Subagents | Parallel workers | Separate agents for: pattern discovery · plan drafting · scoped implementation · risk/security review. Each gets task + context + constraints + expected output. |
| Model selection | Cost & risk control | Default: fast models for scoped edits. Escalate to stronger models only for architecture, debugging, or complex business logic. Current recommendation: Anthropic Claude Opus and Sonnet. Current team recommendation: Anthropic Claude Opus and Sonnet are considered best-in-class at this time. MCP (Model Context Protocol) integration is actively being tested across projects. |
Principle 3
Plan Before Every Execution
Many teams miss significant ROI at this stage. AI amplifies direction, so mistakes at this speed can result in extensive and costly rework.
| Plan Element | Why It Matters |
|---|---|
| What changes and why | Prevents scope drift → AI fills ambiguity with assumptions |
| What is out of scope | Explicitly bounded → no implicit inclusions |
| Sequence of steps | Prevents parallel conflicts and ordering mistakes |
| Risks and failure modes | Named before they happen → not discovered in production |
| How we verify | Defined before code is written → not retrofitted after |
| How we roll back | Required → not optional. In the definition of done from day one. |
If you're just starting:
Automated gates are faster to set up than manual review processes ? and they scale with your team.
If you've hit the wall:
This is where regressions escape. A governed pipeline catches failures before they reach main.
Principle 4
Verification Is a Pipeline, Not a Feeling
Verification bridges the gap between AI-generated code and safe, scalable merging. It must be automated, enforced, and consistent → regardless of deadlines.
| Automated gate | Lint → Type-check → Unit tests → Build → Integration tests. Fix cheap failures before running expensive checks. |
| Human checklist | Can you explain it end-to-end? Is it the right change? Does it duplicate existing code? Are module boundaries respected? Is it secure? Are resources cleaned up? Is it testable and observable? |
| The 3am test | "If this breaks production at 3am, can we debug it without the AI conversation context?" If no — it is not production-ready. |
Principle 5
Code Quality Rules for AI Generation
AI failure modes are predictable. Establish guardrails in advance to prevent these issues from reaching your codebase.
| Codebase-first rule | If there's 80%+ overlap with existing patterns → modify, don't create a new layer. |
| Common AI failure modes | Dead code · magic values · narrating comments · over-abstraction · shallow error handling · missing cleanup · direct env access · import disorder |
| Clarification threshold | If confidence is below 90% on intent → ask, don't guess. Confident-sounding wrong code is worse than an explicit question. |
Principle 6
TDD Workflow That Catches Misunderstandings Early
A five-step process that keeps humans in control at every inflection point.
| Step | Who | What |
|---|---|---|
| 1 | Human | Writes spec — contract + edge cases — defines what must never break |
| 2 | AI | Generates tests: scaffolding from spec |
| 3 | Human | Reviews tests: quality check + gap identification |
| 4 | AI | Implements — to satisfy test contracts, not to satisfy a prompt |
| 5 | Human | Reviews output: implementation + production concerns |
If you're just starting:
Build this in from week one. Retrofitting observability is 3x harder than shipping it with the feature.
If you've hit the wall:
This is where incidents become preventable, not just survivable.
Production is where trust is established, but many AI-first rollouts lose it at this stage. The loop must close.
Operational Standards
| Area | Standard |
|---|---|
| Observability | Every AI-assisted change ships with logs, metrics, and traces aligned to the feature. No exceptions. |
| Alerting | Riskier modules get stronger alerting and staged rollout patterns. |
| Incident readiness | Incidents must be diagnosable without prompt history — runbooks and rollback steps required before release. |
| Post-release validation | Error rates · latency · throughput · drift signals — checked after every release, not just major ones. |
The Continuous Improvement Loop
The Flywheel
Rules → Plan → Execute → Verify → CI → Merge → Monitor → Retrospective
Every escaped issue must produce at least one of:
- A new rule — so AI doesn't generate the same problem again
- A new test — so the pipeline catches it automatically next time
- A new skill (procedure) — so the team handles it faster if it recurs
"This is how the system tightens over time — and how AI becomes a controlled accelerator, not a risk multiplier."
First Results: What We're Seeing in Practice
From Ardas development teams using AI-assisted delivery — April 2026.
What?s measurably faster
- Time to identify root cause — noticeably reduced
- Time to find and evaluate a solution — noticeably reduced
- Tooling iteration cycle: new tools evaluated and adopted weekly
What?s still being measured
- Overall feature delivery velocity — data collection ongoing
- Early indicators are positive, but results will be published only when fully supported
What?s confirmed
- The workflow schema → planning, research, implementation, self-validation — is valid and stable
- Confidence in the flow has grown consistently
We will update this section as additional data becomes available.
What Changes When This Is Implemented
| Before | After |
|---|---|
| More output, less confidence | Output with full traceability |
| Planning skipped under pressure | Planning is the starting gate — always |
| Ghost ownership on merged PRs | Named human owner per change |
| Incidents require the AI thread to debug | Runbooks + observability — no thread needed |
| Regressions escape CI | Gates catch failures before they reach main |
| AI rollout stalled by fear of breakage | Incremental phases — expand when each one is working |
| Time lost to problem identification and solution search | Measurably faster — developers report clear reduction in time to identify problems and find solutions |
Implementation Path: 3 Weeks to a Governed AI Workflow
You don't need to transform everything at once. This path is designed to be incremental — each week delivers standalone value and reduces risk before the next phase begins.
| Week | Focus | Deliverables |
|---|---|---|
| Week 1 | Foundation | Set rules + plan template · define verification order · add branch protections · establish scope-bounding habit |
| Week 2 | Build layer | Planning is the starting gate — always |
| Week 3 | Close the loop | Named human owner per change |
Internal Workshops: Operationalise Across Your Team
Ardas runs structured workshops aligned to the full delivery lifecycle, whether you're installing this from scratch or reinforcing a team already in motion.
Discovery & Delivery Readiness (Before Build)
| Requirements & Acceptance Criteria | 3h | Testable outcomes · edge cases · constraints |
| Architecture & Integration Boundaries | 3h | Internal systems · external services · failure modes |
| Observability & Release Plan | 3h | Monitoring strategy · rollout plan · rollback readiness |
AI Codegen Workshop Series (Build + Verify)
| Workshop | Time | Focus |
|---|---|---|
| AI Codegen Foundations | 2h | Core operating model and mental model shift |
| Planning & Context Mastery | 3h | Plan templates · scope bounding · execution context |
| Rules, Skills & Tooling Setup | 2h | Guardrails · skill packs · subagent configuration |
| Verification & Testing with AI | 2h | TDD workflow · test review · CI gate setup |
| AI Workflow for Leads & Reviewers | 2h | Review standards · ownership model · escalation |
Production Support Enablement (After Release)
| Workshop | Time | Focus |
|---|---|---|
| Monitoring & Incident Playbooks | 2h | Signals · runbooks · escalation · rollback |
| Retrospective → Rules/Test Updates | 2h | Convert escaped issues into tighter gates |
Ready to build with AI — without the risk of losing control?
Whether you're starting your first AI workflow or fixing one that lost production trust, we'll show you exactly where to begin.
Start With a Workflow AuditWe review your rules, CI gates, ownership model, and incident readiness.
You receive a prioritised remediation plan within 5 business days.
Table of content
See also
Feb 24, 2026