Rewriting the CV Playbook: The Old Way vs. the New Way of Doing Computer Vision

Key insights
- CV has transitioned from R&D to production-ready infrastructure. Modern computer vision isn’t just experimental anymore — it can now be deployed at enterprise scale with predictable results and workflows that shorten time to value from months to hours.
- Scalability and maintainability are the primary competitive differentiators. Traditional CV projects often struggled with scaling and drift. Today’s platforms and MLOps approaches make continuous deployment and monitoring feasible, reducing the long-term operational burden.
- Data quality and edge-ready design drive real-world performance. High-quality, annotated datasets and edge-optimized inference pipelines are key to reliable real-time computer vision systems. Ignoring data variability or hardware constraints can break deployments post-pilot.
- Integration and deployment choices are business, not just tech decisions. The success of a CV system depends as much on integration with existing business systems and workflows as on model accuracy — something expert partners like Ardas can help navigate.
Computer vision (CV) has already moved from research labs into real-world business workflows at scale. The market itself is on a steep growth path, projected to reach $58B–$63B by 2030 (as per Grand View Research, and MarketsandMarkets).
Yet, for many companies, deploying CV still feels harder than it should be. CTOs face long development cycles, unpredictable accuracy, scaling issues, and high maintenance costs. The gap between what’s technically possible and what’s feasible to deploy has historically slowed adoption.
Today, that gap is closing; at least Ardas team is experiencing this shift. With new platforms, building and deploying CV solutions takes hours instead of months. In our case, we worked with EyePop.ai — and what follows isn’t a promotional piece, but a look into our team’s hands-on experience: the challenges we encountered, how we addressed them, and the results we have achieved so far.
The Hidden Work Behind Traditional CV Models
CTOs and tech teams can relate: building computer vision solutions manually is more than “just running a model.”
Here’s what it used on average to involve:
| STAGE | OLD WAY | BUSINESS IMPACT |
| Model Selection | Choose, download, or train from scratch (ONNX, TensorFlow, PyTorch), validate accuracy/latency, repeat with updates | Long R&D cycles, high experimentation cost |
| Preprocessing | Media server setup, input decoding, resizing, normalization (RGB/BGR, pixel scaling) | High infra complexity, error-prone pipelines |
| Inference | Efficiently load model, pass tensors, analyze raw output | Demanded AI expertise + constant optimization |
| Postprocessing | Argmax, coordinate scaling, convert to JSON outputs | Custom dev effort, fragile integrations |
| Deployment & Maintenance | Optimize for CPU/GPU/edge, monitor drift, retrain, scale APIs | Ongoing resource drain, tough to scale |
For early adopters, this mean long timelines, steep costs, and fragile systems.
The Old Way of CV Projects: They Worked, But at a Cost
Between 2014 and 2016, Ardas received its first requests for face recognition and image-based modules. These projects were interesting, groundbreaking, but the challenges of a traditional CV were very real.
Case #1: Real-Time Face Recognition for Secure Field Access (US Agriculture)
Manual ID checks at checkpoints were slowing client’s operations. Their CTO wanted a facial recognition module for secure, contactless access.
Client's Challenges
- Long R&D cycles for model selection and validation;
- Complex preprocessing (media servers, input decoding, resizing);
- Fragile postprocessing pipelines (coordinate scaling, JSON conversion);
- Heavy optimization work for CPU/edge deployment.
Our Solution
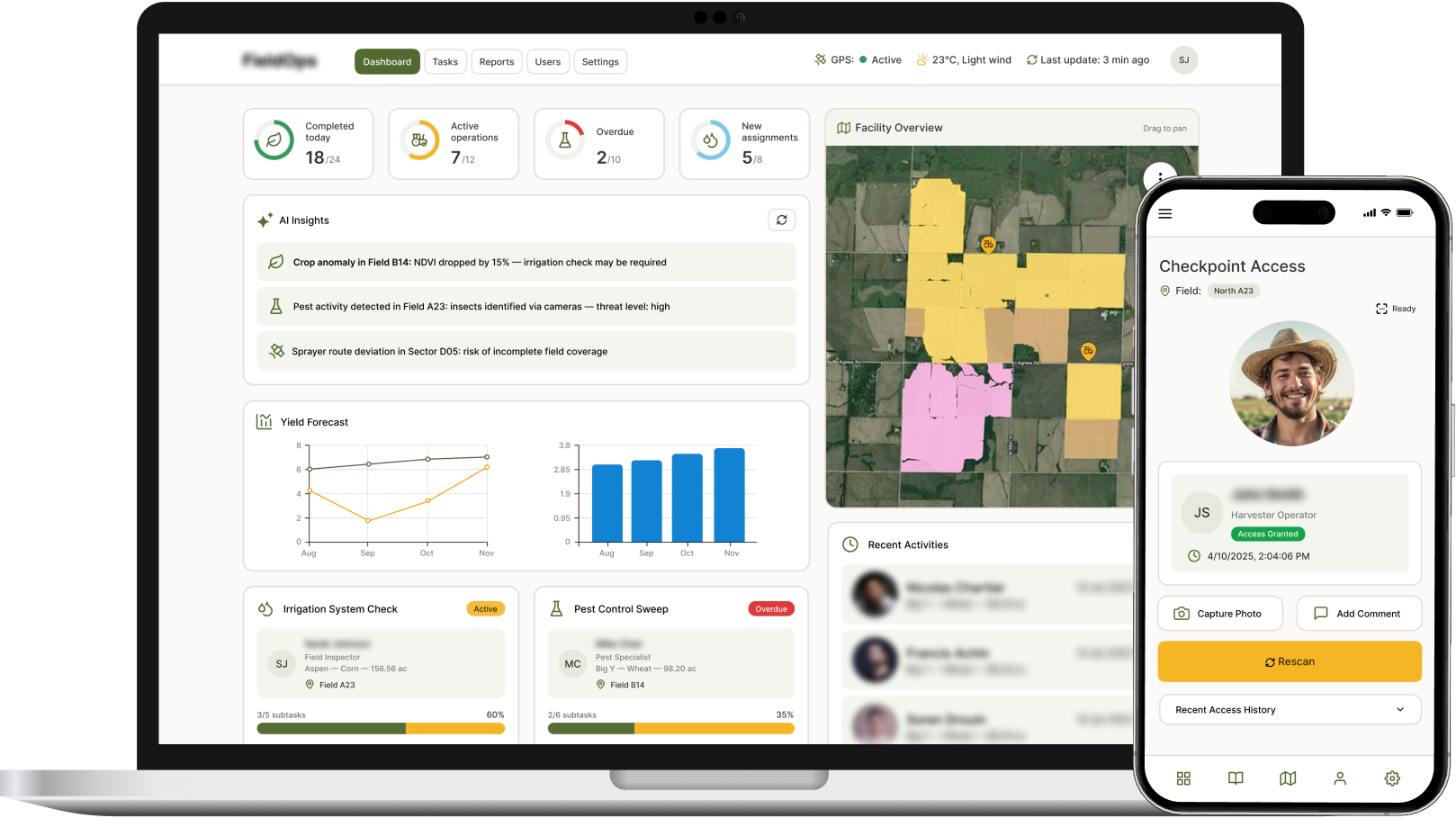
- Edge-compatible recognition module integrated with internal systems;
- Worked both online and offline with secure syncing;
- Logged entries/exits automatically.
Tech Stack: Python, TensorFlow, Keras, OpenCV, DLib
Delivered Results:
- 80% accuracy in real-world conditions;
- Reduced staffing load;
- Real-time tracking across multiple sites;
- Time to value for CV module: 4 months.
Case #2: Parking Management SaaS for an African Municipality
Unique plate formats, poor image quality, and the absence of existing recognition solutions made this project challenging, in addition to manual models training.
Client's Challenges
- Preprocessing complexity with low-quality images;
- Manual AI training loop to improve accuracy;
- Integration effort for mobile + operator dashboards;
- Ongoing optimization for scalability and reliability.
Our Solution
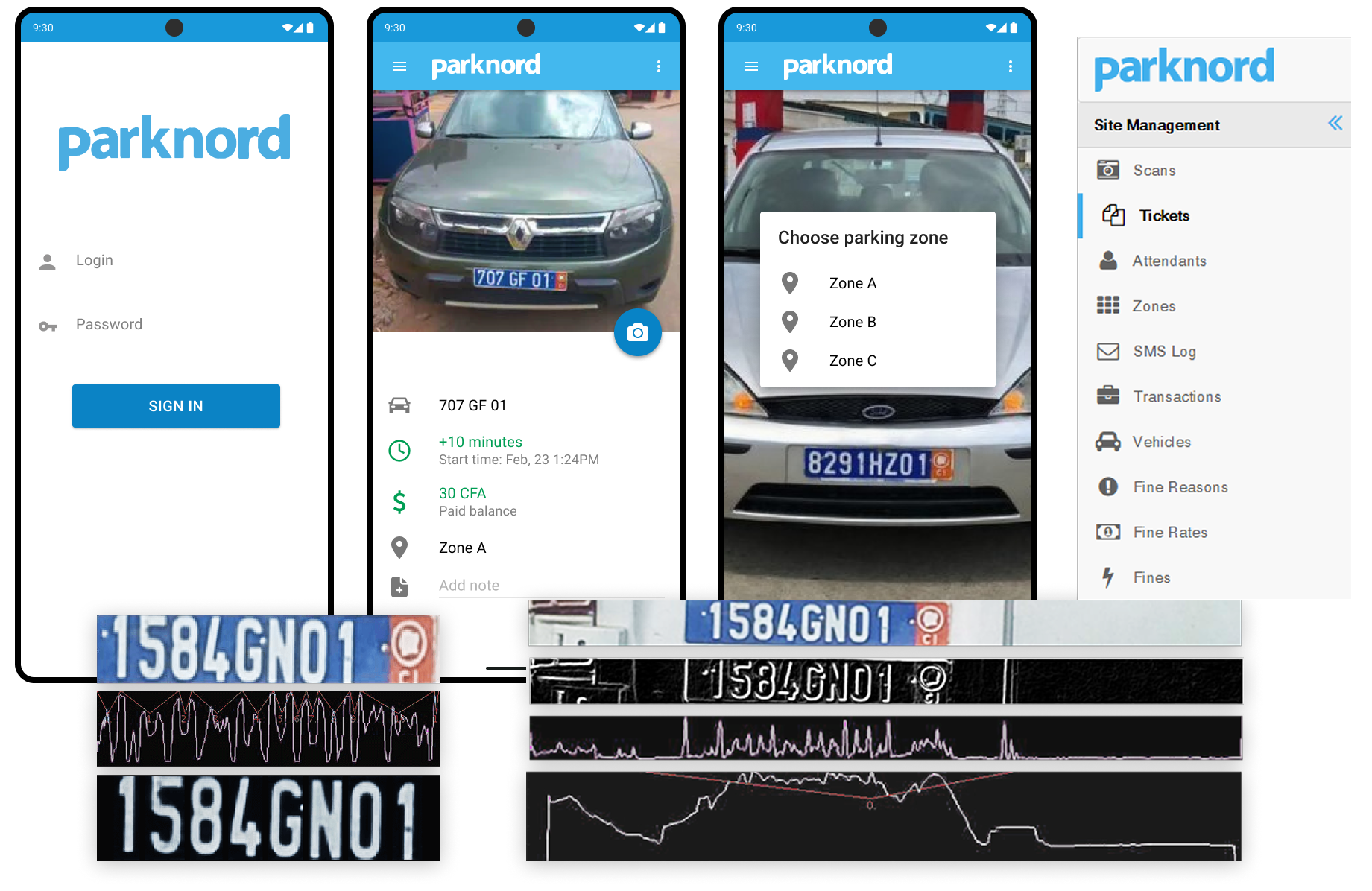
- PoC → MVP with custom plate recognition.
- SaaS platform with mobile apps, operator dashboards, real-time payments.
- AI teaching loop improved recognition accuracy from 50% → 85%
Tech Stack: PHP, Symfony, OpenCV, OpenALPR, Tesseract, AWS, Docker, Kubernetes
Delivered Results:
- Adopted by multiple municipalities;
- Financial transparency through real-time reporting;
- Scalable SaaS with reliable infrastructure;
- Time to value for CV module: 3 months.
Read the full case study.
The New Era: Effortless Computer Vision
Fast forward to today.
Quick note, again: this isn’t a promo piece. It’s our team’s story of using the EyePop platform, hitting roadblocks, and figuring out processes and effective solutions along the way.
Why EyePop?
Agree, seeing an AI tool in action often makes the difference compared to reading yet another “next-gen AI miracle” loud announcement.
We first met the EyePop team at GenAI Mixer: EdgeAI in action by Qualcomm, AI LA at the beginning of 2025.
Since then, they’ve significantly matured their platform, shipping bi-weekly updates that strengthen server performance and introduce features such as Product Report (already live), upcoming fine-tuning for VLMs, a video AI assistant, and hybrid deployment environments.
The platfrom recent updates focus on:
- Greater stability;
- Faster processing;
- Bug fixes and reliability improvements;
- Broader codec and video format support.
What the Platform Offers
EyePop provides a no-code environment for building and training custom computer vision models. Ardas role is to take those models and embed them into scalable, production-ready applications.
Key paltform capabilities include:
- Auto-labeling to accelerate dataset preparation;
- End-to-end training with built-in optimization;
- Flexible deployment: cloud, edge, or hybrid;
- Full ownership of data and model roadmap;
- Effortless scaling as new use cases emerge;
- Time to value: most users can train and deploy a custom model in hours, not months.
How It Works
- Define your target → Select objects or conditions to detect
- Upload or connect data → Images, video, or live streams
- Train your model → Prioritization + auto-labeling
- Deploy → Cloud, edge devices, or integrated workflows
- Iterate → Refine models as needs evolve
- Result: businesses move from proof-of-concept to production faster and at a fraction of the cost.
Key Considerations
Objectively, adoption is not entirely plug-and-play. It means your tech team will need time to:
- Get familiar with the platform and its documentation;
- Experiment with models in a safe environment;
- Ask questions, explore resources, and adapt workflows.
The same goes for the client side. Providing initial datasets, photos, videos, or streams, is not just a matter of uploading files. Quality inputs require effort: choosing the right formats, angles, and conditions so the model can learn effectively.
It’s a process, not a one-click setup, but once the learning curve is passed, the platform can deliver long-term efficiency and competitive advantage.
Real-World Example: Pickleball Video Analysis
We’re currently working with EyePop.ai platform on an app for pickleball skill development, designed to demonstrate how computer vision can deliver practical value beyond traditional enterprise use cases.
The application workflow is structured as follows:
- Video capture – players record and upload practice sessions.
- Frame-by-frame analysis – computer vision models evaluate technique in detail.
- Automated feedback – pass/fail results are provided based on coaching criteria.
- Adaptive learning – models adjust as players progress, creating a continuous improvement loop.
At the current stage, we are validating 3D human pose models — with a focus on depth estimation and joint-angle accuracy for elbows, knees, torso rotation, and paddle positioning.
This requires controlled input data from the client: videos recorded with specific reference poses (e.g., elbow at 90°) and multiple camera angles. Running frame-by-frame evaluations against these controlled scenarios allows us to benchmark detection reliability and confirm alignment with actual coaching requirements at scale.
This is just one example of CV being applied beyond traditional industries into sports and personal training.
Will be happy to share more details on this project quite soon.
Conclusion: The CV Playbook Has Changed
This article isn’t about promoting a single tool.
It's about sharing lessons from real experience so CTOs and tech leaders can make informed decisions, working with computer vision projects today.
|
Traditional CV |
New Way for CV |
|
Building CV demanded deep AI expertise, team, large budgets, and long timelines |
Platforms like EyePop.ai enable teams to deploy CV faster, more cost-effectively, and at scale. |
For CTOs, this means shifting CV from a risky R&D project into a practical, repeatable, revenue-driving capability.
At Ardas, we’ve lived through both eras from early, hard-won CV projects to today’s self-service AI-powered workflows. If you’re exploring computer vision for your business, let’s talk about how to make it faster, leaner, and future-proof.
Ready to explore an effortless CV?
Let’s see how we can help you build smart system that lasts
FAQ
What’s the biggest difference between traditional and modern computer vision deployments for enterprises?
Traditional CV required heavy manual work and long timelines. Modern CV uses platform-based and MLOps-driven deployment, enabling faster, scalable, and production-ready systems.
How does Ardas support computer vision initiatives beyond selecting a platform like EyePop?
Ardas embeds CV models into scalable, resilient systems, handles integration with existing enterprise infrastructure, and implements MLOps pipelines so companies can maintain accuracy, monitor drift, and update models reliably as business conditions evolve. This helps shift CV from R&D to a sustainable business capability.
What are common pitfalls in CV projects — and how can they be avoided?
Common issues include poor quality training data, lack of model monitoring, and failure to account for distribution shifts that occur in real environments. Addressing them requires robust data governance, continuous retraining strategies, and edge-aware deployment architectures.
Should a company try CV in-house first or partner with experts?
Early experimentation is useful, but large-scale deployment often depends on cross-disciplinary expertise — from data engineering to MLOps. Partnering with experienced teams like Ardas accelerates time to production and reduces technical risk, particularly for multi-site or mission-critical systems.
When should a company involve Ardas in a computer vision project?
When moving from pilot to production — especially if scalability, reliability, and long-term maintainability are business-critical..